
On 30 June 2026 Anthropic launched Claude Sonnet 5. In short, it is a model that sits close to their top model Opus 4.8, but costs far less. For anyone who wants to put Claude for business into real use, it is the most important news in a while.
Not because another model is a big deal in itself. But because the price is now low enough that AI can run on real, recurring tasks every day, not just in trials. That is the shift from testing AI to operating it.
The one point to take from this: when a good model gets cheap, the value shifts from the model to the implementation. Access to a strong model is no longer what separates winners from losers. How it gets put to work in your own workflows is.
Anthropic: Introducing Claude Sonnet 5 (30 June 2026) →
Introductory price of 2 dollars per million input tokens and 10 dollars per million output tokens through 31 August 2026, then 3 and 15 dollars. Opus 4.8 costs 5 and 25 dollars.
What Claude Sonnet 5 is
Sonnet 5 is the most agentic Sonnet model to date. Agentic means the model can plan on its own, use tools like a browser and a terminal, and work through a task in several steps without being led by the hand.
Anthropic describes it as a clear step up from its predecessor Sonnet 4.6 on reasoning, tool use, coding and knowledge work, and as close to Opus 4.8 in performance. It is available from day one across all plans, is the default model on Free and Pro, and can be used as claude-sonnet-5 on the Claude Platform and in Claude Code.
A key new feature is what Anthropic calls effort levels. You can turn up or down how much compute the model spends on a task. At a low level it is cheap and fast. At a high level it can match Opus 4.8 on some tasks. Anthropic shows this on two standard evaluations, one for agentic search (BrowseComp) and one for computer use (OSWorld-Verified), where Sonnet 5 covers a far wider range of cost and performance than its predecessor. In practice you choose the balance of price and precision per task, rather than switching model. Anthropic has also raised rate limits, the ceiling on how much you can send through the model, across Chat, Cowork, Claude Code and the Claude Platform, precisely because the higher effort levels use more tokens.
Price is the core of it. On the API, Sonnet 5 costs an introductory 2 dollars per million input tokens and 10 dollars per million output tokens through 31 August 2026. After that, 3 dollars in and 15 dollars out. Tokens are the pieces of text a model computes in, and what pricing is measured on. For comparison, Opus 4.8 costs 5 dollars in and 25 dollars out.
One important catch: Sonnet 5 uses a new tokenizer, a new way of splitting text into tokens. The same text can therefore become more tokens than before, roughly 1.0 to 1.35 times as many. Anthropic set the introductory price so the switch from Sonnet 4.6 is roughly cost neutral. The point is that a lower price per token does not translate one to one into a lower bill. It has to be worked out on your own usage.
Safety, cyber and safeguards
Sonnet 5 is not just faster and cheaper. It also measures as safer than its predecessor on several fronts, which is worth knowing before you set an agent to work on its own. Anthropic reports lower rates of hallucination and of sycophancy, the model tendency to tell you what you want to hear rather than the right answer, compared to Sonnet 4.6. On Anthropic automated behavioural audit, which tests a wide range of undesirable behaviour, Sonnet 5 scores lower, meaning safer, than 4.6, though slightly higher than the stronger Opus 4.8 and Claude Mythos Preview.
On the cyber side the picture is reassuring for most companies. On a test of whether the model could build a working exploit against the Firefox browser, both Sonnet models scored 0.0 percent. Because Sonnet 5 is nonetheless a little stronger than its predecessor, it launched with cyber safeguards enabled by default, the same as in Opus 4.7 and 4.8. For genuine cyber security work that needs fewer guardrails, Anthropic itself recommends Opus 4.8. For you the default safeguards mean two things: a lower risk profile, and the occasional false refusal in legitimate coding work. The latter is an expectation to set with your developers up front.
Here is my take
Here is my take, and I flag it as opinion, not fact.
Make Sonnet 5 your default. Against Sonnet 4.6 it is a clean upgrade, and the introductory price sits below the old Sonnet price. Keep Opus 4.8 only for the very hardest tasks and for cyber work that needs fewer guardrails. On Sonnet 5 you can often get close to Opus by turning the effort level up, and still pay less.
And be honest about the savings. Work them out on real token usage, not on the per-token sticker price. The new tokenizer means two models doing the same task do not necessarily use the same number of tokens. Anyone promising you a halved bill from the price alone has not done the maths.
Sonnet 5 versus Opus 4.8: when to use which
So, when to use which. Here are the actual API prices per million tokens, taken from Anthropic pricing page on 1 July 2026:
| Model | Input | Output |
|---|---|---|
| Sonnet 5 (intro to 31 Aug) | 2 USD | 10 USD |
| Sonnet 5 (standard after 31 Aug) | 3 USD | 15 USD |
| Opus 4.8 | 5 USD | 25 USD |
| Haiku 4.5 | 1 USD | 5 USD |
Choose Sonnet 5 as the default for most agentic work, coding and knowledge work. Choose Opus 4.8 when a task needs the absolute best regardless of price, or for cyber work with fewer guardrails. Choose Haiku 4.5 when speed and low cost matter most and the task is simpler. The rule is simple: start on Sonnet 5, and only move up to Opus when a concrete task proves it needs it.
What the price drop actually changes
Here is the most important consequence, and it is not technical. As recently as last year, access to a good model was an advantage in itself. It is not any more. When a model close to top tier costs the same as a mid-tier model did a year ago, the question is no longer which model, but what you do with it.
That moves the work from procurement to implementation. The company that gets the most out of Sonnet 5 is not the one that has access to it, because everyone does. It is the one that has put it into the right workflows, with the right data, the right safeguards and a team that can keep building after the consultant leaves. That is exactly where the difference sits now.
In concrete terms, a pilot that made sense to test on an expensive model can now go into real production without blowing the budget. And the tasks you set aside as too expensive are worth another look. This is not a technology decision. It is an operations decision.
What it means for Nordic B2B SaaS
For a Nordic B2B SaaS company this is a direct win. You already build product, and now a model close to top tier can run agentically inside your flows at a price that holds in the unit economics. Think support triage, research, draft replies, lead qualification and data cleanup. What used to be too expensive to put on a top model becomes realistic.
The effort levels are worth using deliberately here. Run the simple, high-volume tasks at a low level where the price is lowest, and only raise the level on the tasks where quality really pays off. Start with the workflow that eats the most hours, measure the effect, and expand from there. This is exactly the kind of implementation Brinvik does: Claude put directly into your business, under your own data and security rules, so your own team can keep building after I leave.
What it means for telemarketing and sales teams
For a sales or telemarketing team this is about hours. A customer quote from the launch describes Sonnet 5 finishing a two-part job end to end: update account tiers in Salesforce and send a launch message to enterprise contacts. That is Anthropic own customer example and not independently verified, but the direction is clear.
Account research, follow-up on stalled threads and meeting prep can run agentically at a price that makes sense. It is the same engine that lets an AI agent on your website hold a longer, context-aware conversation with a lead and qualify it before a rep even touches it. At the new price it becomes realistic to let the agent run on every single lead, not just the biggest.
What it means for professional services firms
For law firms, accountants, agencies and consultancies, time is billable, and routine work steals from it. Sonnet 5 makes it cheap enough to hand drafting, research, summaries and document review to a model that carries the task to a finish and checks its own work.
The human keeps the responsibility and the professional judgement. The model takes the volume. The key is to set it up so sensitive client data is handled correctly and the quality can be documented. The lower rates of hallucination and sycophancy in Sonnet 5 help here, but they do not remove the need for a human who reads it through. That is a setup job, not a technology you simply switch on.
What it means for founders and scale-ups
For a founder team or a scale-up the short version is near Opus quality at a price you can build on. For prototyping and coding it is an obvious new default, and you can turn the effort up on the hard tasks instead of switching to a more expensive model.
Two practical points. The introductory price only runs through 31 August, so budget for 3 and 15 dollars after that when you plan for the autumn. And the new tokenizer means you should measure real usage rather than trust price per token alone. Build a small usage estimate on your own typical prompts before you promise an investor a number.
GDPR and EU hosting for Nordic companies
For Nordic companies the question is almost always where data is processed. Anthropic offers US-only inference, running entirely in the US, at 1.1 times the price, if a workflow needs it. For you it is more often the opposite, EU processing, that is the requirement. The usual route is to run Claude through AWS Bedrock or Google Cloud Vertex AI in an EU region so data stays in the EU. Settle this before you put personal data on it.
Note too that Sonnet 5 runs with cyber safeguards enabled by default. That is good for the risk profile, but it can raise false refusals in legitimate coding work. Factor that into expectations with your developers. A SOC 2, ISO 27001 or GDPR audit will look at the data processing agreement and at where processing happens before anything else. Get those two things right from the start and the rest is far easier to document later.
If Sonnet 5 is to be set up right from the start, with data processing, access and spend under control so it holds up to an audit, that is exactly what I do for companies. See internal AI tools with Claude, or write to me before you roll it out on real data.
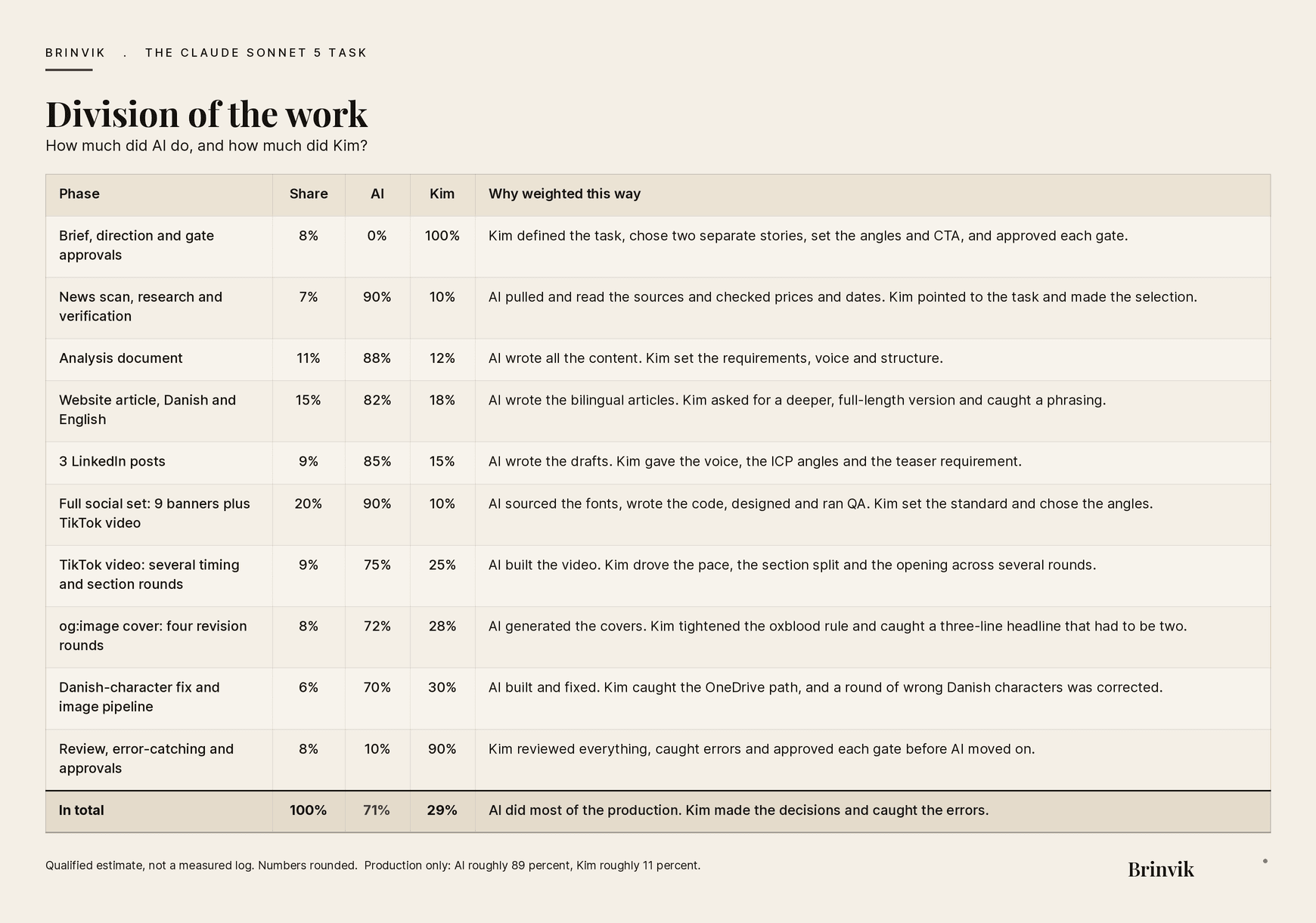
This work was produced in collaboration with AI. Overall: AI roughly 71 percent, Kim roughly 29 percent. Production only: AI roughly 89 percent, Kim roughly 11 percent. The human sets the direction, AI produces the volume. A qualified estimate, not a measured log.
FAQ
Frequently asked questions
On the API, Sonnet 5 costs an introductory 2 dollars per million input tokens and 10 dollars per million output tokens through 31 August 2026, then 3 and 15 dollars. It is also on Claude paid plans and is the default model on Free and Pro. Prices are checked against Anthropic own pricing page.
Not in general. Anthropic describes Sonnet 5 as close to Opus 4.8, but Opus is still strongest on the very hardest tasks. The difference is price: Sonnet 5 costs under half. For most tasks Sonnet 5 is the right choice, and Opus 4.8 is kept for the heaviest work.
Effort levels are a control that sets how much compute the model spends on a task. A low level is cheap and fast. A high level gives better answers on hard tasks and can approach Opus 4.8, but uses more tokens and costs more. You choose the level per task instead of switching model.
A tokenizer is how a model splits text into tokens, the small pieces it computes and bills in. Sonnet 5 uses a new tokenizer, so the same text can become more tokens than before. That is why a lower price per token can still produce roughly the same bill. Work it out on your own usage rather than trusting the sticker price alone.







